К.т.н. Кроль Т.Я., Харин М.А.
Ивановский центр информационных технологий – филиал
ОАО «Электроцентромонтаж»
ИСПОЛЬЗОВАНИЕ ПОСЛЕДОВАТЕЛЬНОСТЕЙ ПРИ ЗАНЕСЕНИИ ДОКУМЕНТОВ В ЭЛЕКТРОННЫЙ АРХИВ
В настоящее время большое значение в работе предприятий имеют электронные архивы документов: бухгалтерских, корреспонденции, уставных, проектной документации и других. Подобные архивы обеспечивают надежно защищенное хранение документов и доступ к ним в соответствии с правами. При занесении документов в электронный архив используется следующая схема: сканирование бумажных документов, распознавание образов и верификация документов, отправка в архив. Более подробно эта схема описана в статье [1].
Однако зачастую документы создаются на основе каких-либо других, например, на основе счета создается накладная, на основе полученной накладной создается приходный складской ордер . При этом в документах повторяются некоторые реквизиты, например, количество, суммы, номенклатура, поставщик. Закономерно возникает вопрос об использовании уже имеющихся в архиве документов при верификации вновь поступающих.
Данную задачу можно разделить на два этапа:
· получение закономерностей перехода атрибутов с документов одного типа на другой;
· использование полученных закономерностей при верификации.
Рассмотрим эти этапы подробнее. Закономерность представляет собой выражение вида:
«Если значение атрибута
![]() документа
документа
![]() типа
типа
![]() равно значению атрибута
равно значению атрибута
![]() документа
документа
![]() типа
типа
![]() , то значение атрибута
, то значение атрибута
![]() документа
документа
![]() равно значению атрибута
равно значению атрибута
![]() документа
документа
![]() с вероятностью
с вероятностью
![]() ».
Здесь
».
Здесь
![]() и
и
![]() – определенные в архиве типы документов,
– определенные в архиве типы документов,
![]() и
и
![]() – определенные в архиве атрибуты документов,
– определенные в архиве атрибуты документов,
![]() и
и
![]() – некоторые документы архива,
– некоторые документы архива,
![]() –
численное значение вероятности. Например, если в некоторых документах типа «Счет» и «Накладная» совпадают значения атрибута «Сумма», то значения атрибутов «Количество» и «Поставщик» совпадут с вероятностью 80%. Отметим также, что в данном случае рассматривается не полное равенство строковых значений, а равенство по особому критерию [2]. Вычислим расстояние Левенштейна между этими значениями и разделим его на среднюю длину строки. Если полученное значение не превышает определенного предела
–
численное значение вероятности. Например, если в некоторых документах типа «Счет» и «Накладная» совпадают значения атрибута «Сумма», то значения атрибутов «Количество» и «Поставщик» совпадут с вероятностью 80%. Отметим также, что в данном случае рассматривается не полное равенство строковых значений, а равенство по особому критерию [2]. Вычислим расстояние Левенштейна между этими значениями и разделим его на среднюю длину строки. Если полученное значение не превышает определенного предела ![]() (например, 7%), то строковые значения можно считать равными.
(например, 7%), то строковые значения можно считать равными.
Для поиска последовательностей будем использовать следующий метод. Выберем два атрибута
![]() и
и
![]() , по которым будет идти поиск. Используя настройки архива, найдем подмножество типов архива
, по которым будет идти поиск. Используя настройки архива, найдем подмножество типов архива
![]() таких, которые содержат оба этих атрибута. Очевидно, что для существования каких-либо последовательностей множество
таких, которые содержат оба этих атрибута. Очевидно, что для существования каких-либо последовательностей множество
![]() должно содержать как минимум 2 элемента. Начнем перебор документов типа
должно содержать как минимум 2 элемента. Начнем перебор документов типа
![]() из множества
из множества
![]() . Пусть значение атрибута
. Пусть значение атрибута
![]() равно
равно
![]() , тогда выберем документы следующего типа
, тогда выберем документы следующего типа
![]() , в которых значение
, в которых значение
![]() также равно
также равно
![]() . Далее сравним значения атрибута
. Далее сравним значения атрибута
![]() в документах. Разделив количество совпадений значений атрибута
в документах. Разделив количество совпадений значений атрибута
![]() на общее количество отобранных документов типа
на общее количество отобранных документов типа
![]() , получим вероятность
, получим вероятность
![]() для данного случая. Сравнивая даты рассматриваемых документов, можно определить, какой из документов был первичным, а какой создается на его основе. Затем будем выбирать документы оставшихся типов
для данного случая. Сравнивая даты рассматриваемых документов, можно определить, какой из документов был первичным, а какой создается на его основе. Затем будем выбирать документы оставшихся типов
![]() (если множество
(если множество
![]() содержит больше двух элементов), в которых значение
содержит больше двух элементов), в которых значение
![]() также равно
также равно
![]() . Соответственно для каждой пары типов составляем закономерности (правила). Далее продолжаем перебор документов типа
. Соответственно для каждой пары типов составляем закономерности (правила). Далее продолжаем перебор документов типа
![]() и составляем правила на их основе.
и составляем правила на их основе.
Таким образом, после выполнения подобной процедуры мы получим список закономерностей-правил. Каждое правило однозначно характеризуется пятеркой
![]() , где
, где
![]() и
и
![]() – атрибуты,
– атрибуты,
![]() и
и
![]() – типы, причем
– типы, причем
![]() – первичный тип,
– первичный тип,
![]() – вторичный,
– вторичный,
![]() – значение вероятности. Далее рассмотрим следующий этап: применение полученных правил.
– значение вероятности. Далее рассмотрим следующий этап: применение полученных правил.
Применение полученных правил происходит на стадии верификации документов при занесении в электронный архив. Суть заключается в следующем: после сканирования и распознавания бумажных документов 100% точность значений атрибутов достигается довольно редко. Поэтому специальный человек должен проверять и редактировать результаты распознавания. Пусть человек верифицирует документ типа
![]() (например, накладная). При начале верификации такого документа необходимо выбрать из полного набора правил такие, где
(например, накладная). При начале верификации такого документа необходимо выбрать из полного набора правил такие, где
![]() . Далее человек подтверждает значение
. Далее человек подтверждает значение
![]() некоторого атрибута
некоторого атрибута
![]() (например, сумма). Из уже отобранного набора правил отбираем такие, где
(например, сумма). Из уже отобранного набора правил отбираем такие, где
![]() и располагаем их по убыванию вероятности
и располагаем их по убыванию вероятности
![]() . Далее подгружаем из архива документы типа
. Далее подгружаем из архива документы типа
![]() , в которых значение
, в которых значение
![]() , составляем список атрибутов
, составляем список атрибутов
![]() и их значений. Эти значения необходимо выдать пользователю при верификации соответствующих атрибутов, причем наиболее вероятное значение должно быть первым в списке.
и их значений. Эти значения необходимо выдать пользователю при верификации соответствующих атрибутов, причем наиболее вероятное значение должно быть первым в списке.
После верификации необходимо произвести корректировку правил. Для этого нужно средствами архива получить количество
![]() документов типа
документов типа
![]() , в которых
, в которых
![]() , среди этих документов выбрать те, в которых
, среди этих документов выбрать те, в которых
![]() , где
, где
![]() – утвержденное после верификации значение. Количество таких документов обозначим
– утвержденное после верификации значение. Количество таких документов обозначим
![]() . Тогда новое значение вероятности
. Тогда новое значение вероятности
![]() .
.
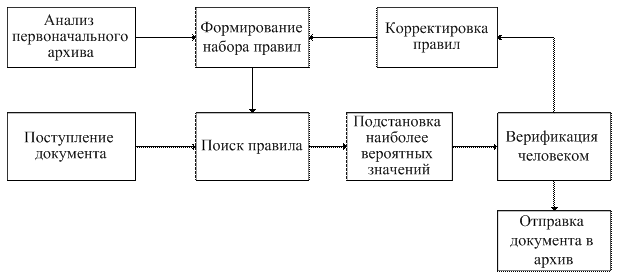
Рис. 1 . Последовательность работы
На рис. 1 приведена последовательность работы, представленная в виде схемы.
Использование данного метода позволит ускорить работу верификатора за счет подстановки наиболее вероятных вариантов значений, а также повысить точность и связанность документов. Например, если в потоке документов один и тот же поставщик именуется одинаково, то выполнить поиск связанных документов становится проще. Таким образом, повышается эффективность использования архива.
Список использованных источников:
1. Кроль Т.Я. Схема наполнения электронного архива документами / Т.Я. Кроль, М.А. Харин, П.В. Евдокимов // Материалы первой международной конференции «Автоматизация управления и интеллектуальные системы и среды», Терскол , 20-27 дек.. – 2010. – Т. IV . – С. 53–56.
2. Кроль Т.Я. Методы создания справочника на основе электронного архива / Т.Я. Кроль, М.А. Харин, П.В. Евдокимов // Известия КБНЦ РАН. – 2011. – №1.
3. Дюк В.А. Data Mining – интеллектуальный анализ данных [Электронный ресурс] / В.А. Дюк . – Режим доступа: http :// www . olap . ru / basic / dm 2. asp , свободный.
4. Вопросы извлечения и представления неточных и недоопределенных знаний при автоматизированном построении баз знаний для интегрированных экспертных систем / Г.В. Рыбина, Р.В. Душкин , Д.А. Козлов, Д.Е. Левин, В.В. Смирнов, М.Л. Файбисович // Третья международная летняя школа-семинар по искусственному интеллекту для студентов и аспирантов ( Браславская школа, 1999): сб. науч . тр. – Мн.: БГУИР, 1999. – С. 191–198.
5. Арустамов А. Анализ бизнес информации – основные принципы [Электронный ресурс] / А. Арустамов . – Режим доступа: http://www.basegroup.ru/library/methodology/analysisbusinessdata/, свободный.