Наши конференции
В данной секции Вы можете ознакомиться с материалами наших конференций
II МНПК "Спецпроект: анализ научных исследований"
II МНПК"Альянск наук: ученый ученому"
I Всеукраинская НПК"Образовательный процесс: взгляд изнутри"
II НПК"Социально-экономические реформы в контексте европейского выбора Украины"
III МНПК "Наука в информационном пространстве"
III МНПК "Спецпроект: анализ научных исследований"
I МНПК "Качество экономического развития"
III МНПК "Альянс наук: ученый- ученому"
IV МНПК "Социально-экономические реформы в контексте интеграционного выбора Украины"
I МНПК "Проблемы формирования новой экономики ХХI века"
IV МНПК "Наука в информационном пространстве"
II МНПК "Проблемы формирования новой экономики ХХI века"
I НПК "Язык и межкультурная коммуникация"
V МНПК "Наука в информационном пространстве"
II МНПК "Качество экономического развития"
IV МНПК "Спецпроект: анализ научных исследований"
ІІІ НПК "Образовательный процесс: взгляд изнутри"
VI МНПК "Социально-экономические реформы в контексте интеграционного выбора Украины"
МНПК «Проблемы формирования новой экономики ХХI века»
IV МНПК "Образовательный процесс: взгляд изнутри"
IV МНПК "Современные проблемы инновационного развития государства"
VI МНПК «Наука в информационном пространстве»
IV МНПК "Проблемы формирования новой экономики ХХI века"
II МНПК студентов, аспирантов и молодых ученых "ДЕНЬ НАУКИ"
VII МНРК "Социально-экономические реформы в контексте интеграционного выбора Украины"
VI МНПК "Спецпроект: анализ научных исследований"
VII МНПК "Наука в информационном пространстве"
II МНК "Теоретические и прикладные вопросы филологии"
VII МНПК "АЛЬЯНС НАУК: ученый - ученому"
IV МНПК "КАЧЕСТВО ЭКОНОМИЧЕСКОГО РАЗВИТИЯ: глобальные и локальные аспекты"
I МНПК «Финансовый механизм решения глобальных проблем: предотвращение экономических кризисов»
I Международная научно-практическая Интернет-конференция «Актуальные вопросы повышения конкурентоспособности государства, бизнеса и образования в современных экономических условиях»(Полтава, 14?15 февраля 2013г.)
I Международная научно-практическая конференция «Лингвокогнитология и языковые структуры» (Днепропетровск, 14-15 февраля 2013г.)
Региональная научно-методическая конференция для студентов, аспирантов, молодых учёных «Язык и мир: современные тенденции преподавания иностранных языков в высшей школе» (Днепродзержинск, 20-21 февраля 2013г.)
IV Международная научно-практическая конференция молодых ученых и студентов «Стратегия экономического развития стран в условиях глобализации» (Днепропетровск, 15-16 марта 2013г.)
VIII Международная научно-практическая Интернет-конференция «Альянс наук: ученый – ученому» (28–29 марта 2013г.)
Региональная студенческая научно-практическая конференция «Актуальные исследования в сфере социально-экономических, технических и естественных наук и новейших технологий» (Днепропетровск, 4?5 апреля 2013г.)
V Международная научно-практическая конференция «Проблемы и пути совершенствования экономического механизма предпринимательской деятельности» (Желтые Воды, 4?5 апреля 2013г.)
Всеукраинская научно-практическая конференция «Научно-методические подходы к преподаванию управленческих дисциплин в контексте требований рынка труда» (Днепропетровск, 11-12 апреля 2013г.)
VІ Всеукраинская научно-методическая конференция «Восточные славяне: история, язык, культура, перевод» (Днепродзержинск, 17-18 апреля 2013г.)
VIII Международная научно-практическая Интернет-конференция «Спецпроект: анализ научных исследований» (30–31 мая 2013г.)
Всеукраинская научно-практическая конференция «Актуальные проблемы преподавания иностранных языков для профессионального общения» (Днепропетровск, 7–8 июня 2013г.)
V Международная научно-практическая Интернет-конференция «Качество экономического развития: глобальные и локальные аспекты» (17–18 июня 2013г.)
IX Международная научно-практическая конференция «Наука в информационном пространстве» (10–11 октября 2013г.)
К.т.н. Кроль Т.Я., Харин М.А.
Ивановский центр информационных технологий – филиал
ОАО « Электроцентромонтаж », Российская Федерация
РАСШИРЕНИЕ МОДЕЛИ ДОКУМЕНТА ЭЛЕКТРОННОГО АРХИВА С ЦЕЛЬЮ ИЗВЛЕЧЕНИЯ И ИСПОЛЬЗОВАНИЯ НАКОПЛЕННЫХ ЗНАНИЙ
Электронные архивы, позволяющие надежно хранить и получать доступ к большому количеству документов, играют большую роль в работе предприятий, особенно с распределенной структурой. При добавлении документов в архив они проходят через следующие этапы: сканирование, распознавание, верификация и загрузка в архив. Более подробно эта схема описана в статье [1]. Для ускорения верификации были разработаны методы создания справочника [2] и методы использования последовательностей документов [3]. Их суть заключается в извлечении и использовании знаний, уже накопленных в архиве, при верификации вновь поступающих документов. При использовании справочника получаем более быстрое определение и единообразное наименование справочных данных: организации, продукция, контрагенты. При использовании последовательностей – поиск значений атрибутов, остающихся постоянными в некоторой цепочке документов, например, счет – накладная – приходный складской ордер.
В данной статье рассмотрим подробнее следующее:
· модель представления документа, используемую в распространенных системах электронного архива;
· модели, позволяющие реализовать методы повышения скорости и точности верификации, описанные в статьях [2] и [3].
Авторами данной статьи проанализированы такие системы хранения электронных копий документов, как «Электронный архив ЭЛАР», система электронного архива « E - Arch », программный комплекс «СПДС-АРХИВ» и другие. В большинстве из рассмотренных систем применяются модели представления документа, хранящие не только электронный образ документа, но и некий набор данных (атрибуты), позволяющий производить идентификацию и поиск конкретных документов. В общем случае модель должна удовлетворять следующим условиям:
1. В архиве требуется хранить документы разных типов (конструкторские, финансовые, корреспонденция и др.), каждый из которых имеет свой собственный набор атрибутов.
2. Набор типов может иметь иерархическую структуру.
3. Предприятие, где внедряется система, может иметь филиальную структуру, либо несколько основных подразделений.
4. Необходимо обеспечить возможность создания версий документа, в том числе автоматического. Если в двух документах совпадают значения определенных атрибутов, значит, это две версии одного и того же документа.
5. Необходима возможность наращивания количества атрибутов и задания признака их обязательности.
Исходя из данных условий, предлагается следующий вариант модели.
В качестве примера документа рассмотрим письмо с просьбой представить список специалистов, которые будут направлены на обучение (рис. 1). Документ находится в демонстрационной версии архива [6] и доступен для просмотра.
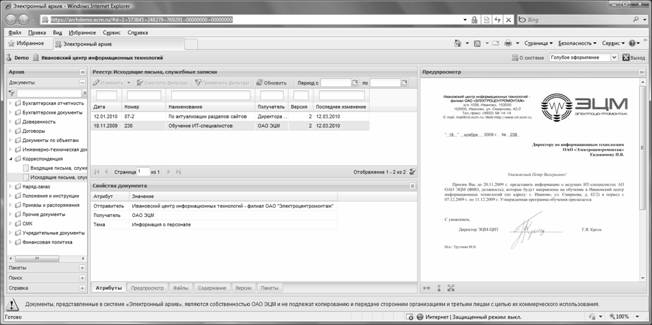
Рисунок 1 . Пример документа
Документ ( doc ) представляет собой набор следующих элементов:
· имя документа ( doc _ name ). В примере «Обучение ИТ-специалистов»;
· регистрационная дата документа ( reg _ date ). В примере 18.11.2009;
· регистрационный номер документа ( reg _ number ). В примере «238»;
· тип документа ( doc _ type ). В примере «Исходящие письма, служебные записки»;
· филиал или подразделение, в котором он был создан ( owner _ filial ). В примере «Ивановский центр информационных технологий». Отметим, что если предприятие не имеет сложной структуры, это значение всегда можно оставить постоянным;
· набор дополнительных атрибутов документа ( doc _ attributes ). В примере три атрибута: «Отправитель», «Получатель», «Тема»;
· признак активности документа ( active _ doc ). В примере документ активен.
Таким образом , doc = { doc_name , reg_date , reg_number , doc_type , owner_filial , doc_attributes , active_doc }. Здесь элемент doc _ type – это некоторый элемент общего множества типов ![]() , doc _ attributes – множество атрибутов документа типа doc _ attribute . Рассмотрим их подробнее. Каждый тип документа doc _ type представляет собой следующий набор:
, doc _ attributes – множество атрибутов документа типа doc _ attribute . Рассмотрим их подробнее. Каждый тип документа doc _ type представляет собой следующий набор:
· наименование типа ( type _ name ). В примере «Исходящие письма, служебные записки»;
· информацию о родительском типе, для поддержки вложенных типов ( parent _ type ). В примере «Корреспонденция»;
· набор атрибутов типа ( type_attributes ).
То есть , doc_type = { type_name , parent_type , type_attributes }. Здесь type _ attributes – это множество атрибутов типа ( type _ attribute ), каждый из которых представляет набор:
· имя атрибута ( attribute _ name ). В примере «Отправитель», «Получатель», «Тема»;
· тип атрибута ( attribute _ type ). В примере все три атрибута имеют строковый тип;
· номер по порядку ( field _ order ). Это поле используется, когда необходимо расположить атрибуты в некотором порядке, отличном от алфавитного . В примере 1, 2, 3 соответственно;
· порядок атрибута при сортировке ( field _ sort _ order ). В примере у всех трех атрибутов 0, порядок при сортировке не определен;
· тип сортировки (восходящая или нисходящая) по атрибуту ( field _ sort _ type ). В примере у всех атрибутов восходящая сортировка;
· признак того, задает ли данный атрибут уникальность документа ( uniqueness _ check ). В примере уникальность задает атрибут «Получатель». Также во всех документах уникальность задают основные атрибуты «Дата», «Номер», «Наименование»;
· обязательность заполнения атрибута ( required ). В примере обязательны для заполнения атрибуты «Отправитель» и «Получатель». Отметим, что если атрибут задает уникальность документа, то он должен быть обязательным для заполнения. Соответственно, атрибуты «Дата», «Номер» и «Наименование» тоже всегда заполняются.
Соответственно , type_attribute = { attribute_name , attribute_type , field_order , field_sort_order , field_sort_type , uniqueness_check , required}. Все атрибуты типа объединяются в множество ![]() .
.
Если атрибуты типа задают некоторые шаблоны документов, то атрибуты документа представляют собой конкретные значения для конкретных документов. При создании документа набор его атрибутов создается на основе атрибутов типа. Атрибут документа ( doc _ attribute ) представляет собой следующий набор:
· атрибут типа ( type _ attribute ). В примере «Отправитель», «Получатель», «Тема»;
· значение атрибута ( value ). В примере значения «Ивановский центр информационных технологий – филиал ОАО ‘Электроцентромонтаж’», «ОАО ЭЦМ» и «Информация о персонале» соответственно;
· признак активности атрибута ( active _ attribute ). В примере все атрибуты активны.
В разных системах загрузка документов происходит по-разному. Например, человек полностью самостоятельно заполняет карточку документа и прикрепляет к ней файл с картинкой. В системе «ДокПрофи™» сканированные документы распознаются и верифицируются с использованием продукта ABBYY Flexi Capture (рис. 2).
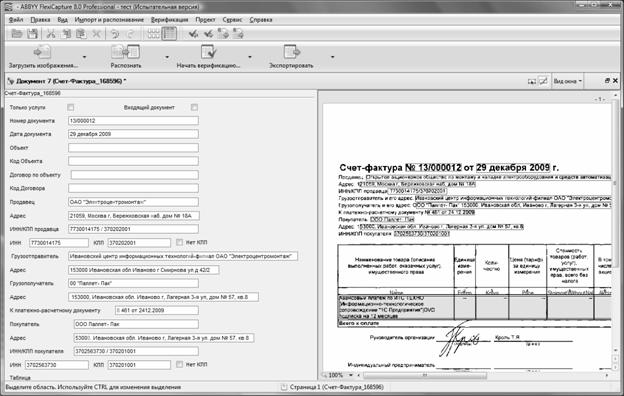
Рисунок 2 . Верификация в системе Flexi Capture
Для быстрого и точного поиска документов атрибуты должны заполняться точно и максимально однообразно. Однако , так как верификацией занимается человек, ошибки, особенно при долгой работе, так или иначе появляются. Для оптимизации процесса и уменьшения количества ошибок были разработаны специальные методы создания справочника [2] и использования последовательностей [3].
Рассмотрим модель данных, позволяющую реализовать методы создания справочника, описанные в статье [2]. Справочник создается на основе документов, загруженных в архив, и его применение может повысить скорость занесения в архив новых документов. Например, анализируя накопленные счета-фактуры, можно выявить следующие закономерности:
· Если атрибут «Продавец» равен «ОАО ‘Электроцентромонтаж’», то атрибут «Адрес продавца» равен «121059, г. Москва, Бережковская наб, дом № 18А» с вероятностью 95%.
· Если атрибут «Продавец» равен «ОАО ‘Электроцентромонтаж’», то атрибут «ИНН продавца» равен «7730014175» с вероятностью 99%.
Тогда если верификатор при занесении нового документа подтверждает, что поле «Продавец» равно «ОАО ‘Электроцентромонтаж’», то можно автоматически подставить значения в поля «Адрес продавца» и «ИНН продавца». В общем случае справочник – это набор правил вида:
«Если ![]() , то
, то ![]() с вероятностью
с вероятностью ![]() ».
Здесь
».
Здесь ![]() и
и ![]() - некоторые атрибуты,
- некоторые атрибуты, ![]() ,
, ![]() и
и ![]() - значения атрибутов,
- значения атрибутов, ![]() – численное значение вероятности. Таким образом, справочник представляет собой набор {
– численное значение вероятности. Таким образом, справочник представляет собой набор {
![]() }.
}.
Рассмотрим модель данных, позволяющую реализовать метод поиска последовательностей в архиве. В качестве примера последовательности можно привести следующую закономерность:
· Если значения атрибута «Сумма» в документах типа «Счет» и «Накладная» совпадают, то значения атрибутов «Количество» и «Поставщик» совпадут с вероятностью 80%.
Методы получения подобных закономерностей описаны в статье [3], там же описан вид получаемых правил:
«Если значение атрибута ![]() документа
документа ![]() типа
типа ![]() равно значению атрибута
равно значению атрибута ![]() документа
документа ![]() типа
типа ![]() , то значение атрибута
, то значение атрибута ![]() документа
документа ![]() равно значению атрибута
равно значению атрибута ![]() документа
документа ![]() с вероятностью
с вероятностью ![]() ».
Здесь
».
Здесь
![]() и
и ![]() – определенные в архиве типы документов,
– определенные в архиве типы документов,
![]() и
и
![]() – определенные в архиве атрибуты типа,
– определенные в архиве атрибуты типа,
![]() и
и
![]() – некоторые документы архива,
– некоторые документы архива,
![]() –
численное значение вероятности. Таким образом, каждое правило однозначно выражается пятеркой
–
численное значение вероятности. Таким образом, каждое правило однозначно выражается пятеркой ![]() , так как конкретные документы существенным образом не влияют на формирование правил. Здесь
, так как конкретные документы существенным образом не влияют на формирование правил. Здесь ![]() .
.
Приведенные модели можно представить в виде следующей схемы (рис. 3).
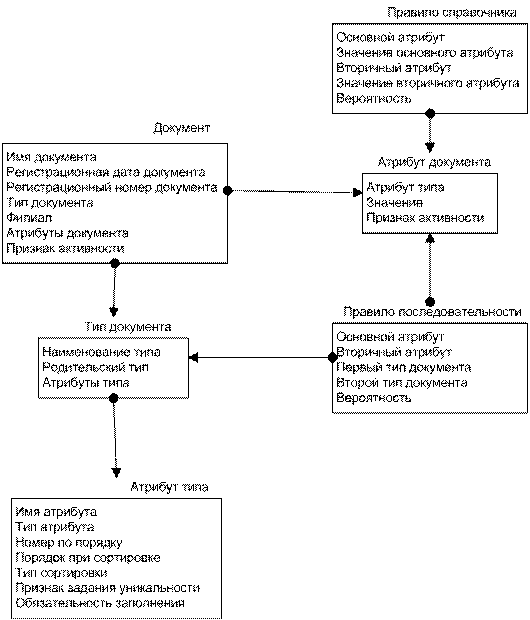
Рисунок 3 . Схема связи моделей данных
Отметим, что приведенные модели для реализации методов не предполагают обязательного изменения уже имеющейся структуры базы данных архива. Если система электронного архива предоставляет интерфейс программирования приложений, то модель может быть реализована в виде отдельной базы данных, связанной с основной посредством специально разработанных компонент.
Также отметим, что схожие модели документов, типов документов и атрибутов используются в других системах электронного архива [7]. Приведенные же модели данных для анализа архива являются вновь разработанными, однако могут быть применены и реализованы в иных системах.
Таким образом, приведенные модели позволяют обеспечить хранение данных, полученных при анализе электронного архива. Полученные данные далее можно применить, например, при верификации документов при занесении в архив.
Список использованных источников:
1. Кроль Т.Я. Схема наполнения электронного архива документами / Т.Я. Кроль, М.А.Харин, П.В.Евдокимов // Материалы первой международной конференции «Автоматизация управления и интеллектуальные системы и среды». – Терскол , 20-27 дек., 2010. – Т. IV. – С. 53-56.
2. Кроль Т.Я. Методы создания справочника на основе электронного архива / Т.Я. Кроль, М.А.Харин, П.В.Евдокимов // Известия КБНЦ РАН. – 2011. – №1.
3. Кроль Т.Я. Использование последовательностей при занесении документов в электронный архив / Т.Я.Кроль, М.А.Харин // VI Международная научно-практическая Интернет-конференция «Спецпроект: анализ научных исследований». – 2011.
4. Наместников, А.М. Построение баз данных в среде ORACLE : практический курс : учеб . п особ . / А.М. Наместников // Федер . агентство по образованию, Гос. образоват . учреждение высш . проф. образования Ульян. гос. техн . ун-т. – Ульяновск: Ульяновский государственный технический университет, 2008. – 117 с .
5. Арустамов А. Анализ бизнес информации – основные принципы [Электронный ресурс] / А.Арустамов . – Режим доступа: http://www.basegroup.ru/library/methodology/analysisbusinessdata/
6. Демонстрационная версия электронного архива «ДокПрофи» [Электронный ресурс]. – Режим доступа: https://archdemo.ecm.ru/
7. Харин, М.А. Обзор средств автоматизированного извлечения знаний и их применение в электронных архивах документов / М.А. Харин // Молодой ученый. — 2010. — №5. Т.1. — С. 106-108.